
Having run the DevOps Enterprise Summit (DOES) for the last three years, I see clear adoption patterns emerging as businesses start expanding the reach of their DevOps approach. Whether that expansion starts in development, architecture or operations, they all start by creating “pockets of greatness” that achieve the incredible outcomes and benefits that we associate with DevOps—and expand from there.
Here’s one strong indication that these DevOps initiatives are creating technical capabilities that are helping their organizations win in the marketplace: About 25% of the DOES speakers who presented in the last three years have been promoted, some more than once. This is an indication that the value they’ve created is recognized by leadership. They’re being asked to make improvements not just in their business unit, but across their entire organization, which consists of thousands, or even tens of thousands, of software engineers.
And that’s not the only common pattern. Before you even talk about a DevOps, large-scale agile transformation, most people will agree that a top-down approach is fundamentally flawed. But I’ll get to that later.
Here are several adoption patterns for a large-scale DevOps transformation, and what these mean to improving success with continuous delivery and customer satisfaction.
How to define “the DevOps enterprise”
In “The DevOps Handbook,” my cop-authors and I defined DevOps as the architecture, technical practices, and cultural norms required to achieve the fast flow of planned work into production, while achieving world-class stability, reliability, availability, and security.
DevOps also enables organizations to create a safe system of work, where small teams are able to quickly and independently develop, test, and deploy code and value quickly, safely, securely, and reliably to customers. This allows organizations to maximize developer productivity, enable organizational learning, create high employee satisfaction, and win in the marketplace.
Those are the DevOps outcomes we want at any scale. For large, complex organizations who’ve been around for decades or longer, we’re seeing evidence that they’re increasingly adopting DevOps principles and practices at scale, ensuring that development, operations, and information security engineers can be as productive as if they were working at a Google, Amazon, Netflix, or Facebook.
Teams work independently
Although DevOps is often associated with frequent deployments per day, it also achieves many other fantastic outcomes, such as increased security and employee satisfaction. But one of the most important attributes is that it allows small teams to develop, test and deploy value quickly and independently to the customer, ideally on-demand, when organizations need it most.
So how do you increase developer and engineering productivity while allowing them to work independently? This is at the heart of the DevOps “at scale” issue.
Take the stunning statistic presented by Ken Exner, Director of Development Productivity at Amazon, that his company does 136,000 deployments per day. They are able to do this because their teams can work independently. In many large, complex organizations, in contrast, no one is working independently. In order to test changes in many applications, often teams in these organizations have to wait in line for an integrated test environment. This means that for months, they may have completed their changes, but they've been shackled to every other team, preventing them from delivering value to customers.
By contrast, with the right architecture (such as Amazon’s), small teams can independently deploy value to the customer without being shackled to other teams. In other words, you can’t do 136,000 deploys a day if every time you want to deploy a change, you must communicate and coordinate with hundreds of other teams. A loosely-coupled architecture makes this possible, reducing the need for these types of hand-offs.
This type of architecture is a clear requirement for doing DevOps at scale, as is elevating the state of the practice across many different teams to get to an end state where everyone is more productive.
To date, there’s no prescriptive framework similar to SAFe, or Nexus, or LeSS in the DevOps community. That’s fine by me, and many in the DevOps enterprise community are using these frameworks. The market will certainly tell us how much need there is for prescriptive frameworks like this.
APIs reduce the need for coordination and communication
One of my favorite patterns for coping with tightly-coupled architectures is the release-planning ritual from the SAFe framework. It often requires a full day for one team to understand the dependencies they have regarding other teams. In other words, your own team needs to ensure that those other teams can complete the work that you need to complete a promised feature.
It’s certainly better that you find out during the release planning process than on release day that one team didn’t complete a necessary work item. If that occurs, you’ll likely need to delay the promised feature until the next release.
But the ideal end state is an architecture that frees you from having to coordinate and communicate and prioritize at this level of intensity. Ideally, you should be able to de-couple yourself from the release train, because you can deliver value to your customers independently.
One of my favorite stories of how powerful the right architecture can be comes from the retailer Target Corp., which a few years ago had a clear business problem. Every time the development team wanted access to product backlogs, orders or shipments, they had to wait six-to-nine months for the systems of record teams to get ready. These delays were caused by multiple point-to-point integrations, which meant that the systems of record teams had to complete their work before the development teams could begin.
So Target launched an “API enablement” project, which led to a stable version of an API. Soon, developers weren’t having to wait for or coordinate with the systems of record teams. Over several years, this capability has enabled 53 different initiatives, including “ship to store,” which is one of the most critical capabilities when you’re a retailer competing with Amazon. Its Pinterest social network integration, its “in store” apps that support the in-store staff, its Starbucks application — all were enabled by the API.
Providing a stable, versioned API helps teams to work independently. When this happens, they are no longer constrained to a once-per-quarter release schedule for delivering new value to the customer.
You might think that this is no different from what people were trying to do 15 years ago with service-oriented architectures. SOA was designed to solve the problem of a tightly coupled architecture, which often meant that new pieces of code would break everyone else’s.
Think of large-scale DevOps and continuous delivery as the logical evolution of what SOA tried to achieve. It’s like SOA is back with a vengeance, but this time we’re all listening.
Knowing when to move toward scaled DevOps
In The Other Side of Innovation, Dartmouth University professors Vijay Govindarajan and Chris Trimble offered a close examination of the sort of failures and successes I’ve seen myself with DevOps. They studied “disruptive innovation,” exploring why is it so difficult for large organizations to do disruptive things. The answer has a lot to do with the success those businesses have enjoyed for years.
Let’s say you are a multi-billion–dollar organization that has dominated your market for decades. You’re clearly great at daily operations. You have processes in place for great product development, a great supply chain, great receivables and superb cash management.
But when you attempt a DevOps initiative, you’ll hear from various corners of the organization: “Change management won’t let us do this,” or “Security won’t let us do that,” or “Software management has a problem with this.” Essentially, what has kept your business going for years—procedures, standards, and modes of bureaucracy— is what prevents disruption.
By contrast, Govindarajan and Trimble exposed a common thread among teams that had successfully disrupted their business. They studied the creation of a small tractor line at John Deere, the first BMW electric car project, the first profitable digital news operation at the “Wall Street Journal.” What these projects all had in common was a small, dedicated team that was held accountable for a result, and for breakthrough performance. And these small teams were also freed from the processes of standards and regulations that governed the rest of their business.
What we’ve seen is that, as the leaders of these teams succeed, they’re put into roles that allow them to make even bigger long-term decisions because everybody has seen that they have the long-term success of the organization at heart.
So what triggers the first step toward larger-scale DevOps? It’s when you have a dedicated team that’s really shown that this will work in the current environment, that you can create great business wins. After that, you’re ready to do more. And the leadership that has been successful may well be the team that elevates the state of the practice for the entire organization, not just one business unit or specific service.
A telling metric for enterprise-scale DevOps
Back in 2011, Amazon wasn’t doing 136,000 deployments per day. But by many standards of excellence, they were doing just fine, at 15,000 deploys per day. You might imagine they needed no improvements.
So, what was the result when they added developers to their staff? The number of deployments per day began to rise. But does that imply a simple, linear relationship between number of devs and number of deploys? No. It’s simply not the case for most companies today.
We decided to explore this phenomenon in our 2016 State Of DevOps Report, which I’ve worked on for four years with Jez Humble, Dr. Nicole Forsgren, and Puppet. One of the mysteries that we looked at was how high-performing organizations always seemed to be increasing the number of deployments per day. Our question was why?
The main difference with high-performing organizations was an increase in the number of developers. In our research we found something astonishing: With the low performers, as the number of developers increased, the number of deployments per day went down. But with the medium performers, as the number of developers increased, the performance stayed about the same.
In other words, the more developers you have in most large companies, where everyone is “shackled” together, the fewer releases you can do per year.
In the high-performing organizations, however, as you increase the number of developers, the number of deployments per day goes up linearly. These organizations are able to increase developer productivity as they add developers.
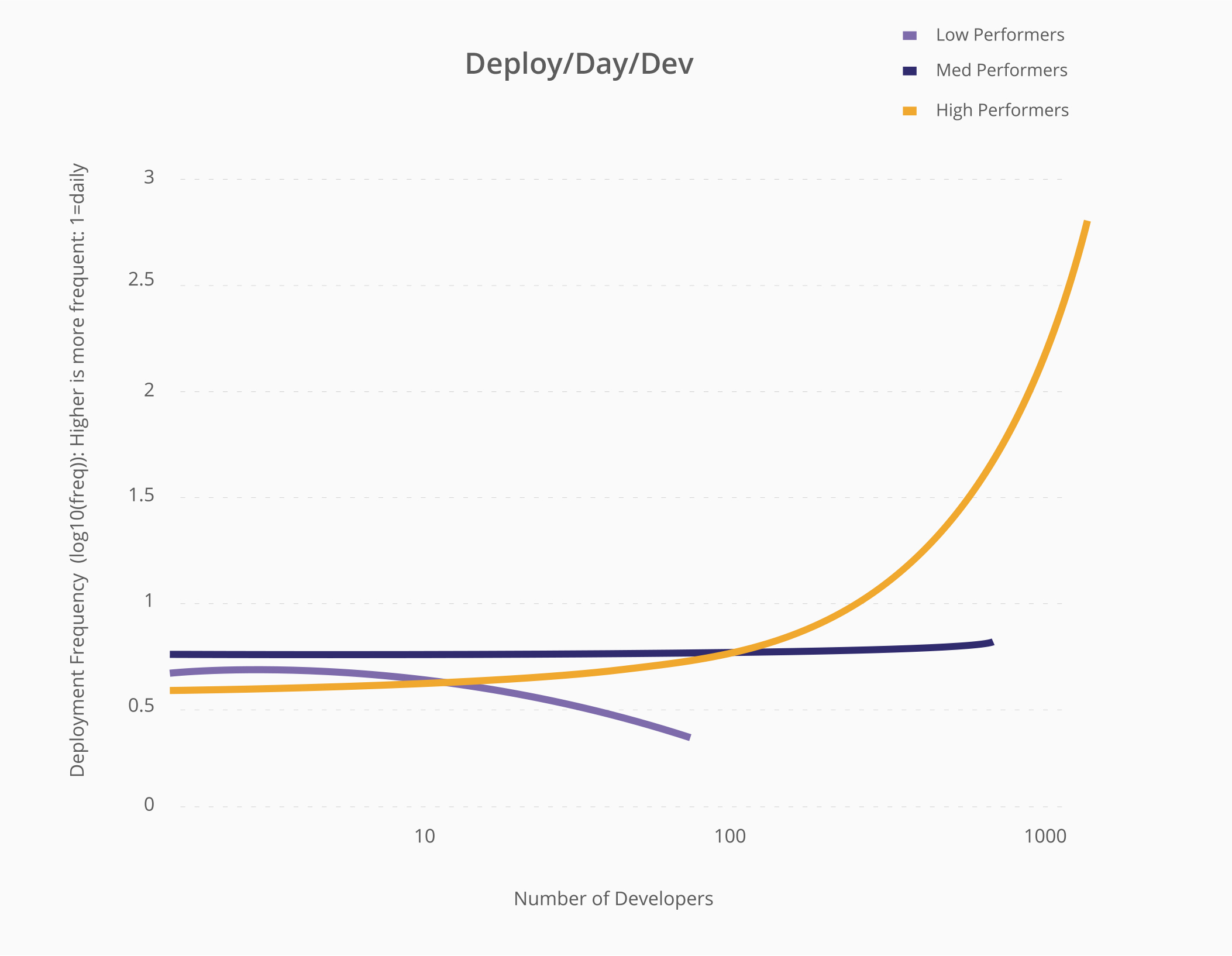
Higher performing development organizations experience a linear improvement in deployment frequency as the number of developers increase. When lower performing teams add developers, the opposite is true. Source: Puppet Labs 2015 State Of DevOps Report.
Frederick Brooks redux? Not with DevOps
I’m not suggesting that the number of deploys per day is itself, necessarily, a great productivity metric. But it does express the degree to which the teams in an organization are able to work independently of each other, and shows the results of that independence.
Frederick Brooks anticipated this in his 1975 book The Mythical Man Month, in which he described a common experience for many software teams: Double the number of developers, double the code integration effort, double the testing effort, and the effort required to deliver value to customers doubles as well.
Allowing teams to deploy value to customers independently is a great improvement. But it’s not the whole solution. If all developers work independently, but they don’t check the code back in, and they only integrate it once a year, then nothing works. I’ve had this experience. It’s as if you’re working on a hundred different waterfall projects.
But what we’re seeing with scaled DevOps is different. Under certain conditions, with the right architecture (like SOA), the right technical practices (like continuous integration and continuous deployment), and the right cultural norms (like boundary spanning and shared DevOps goals), the results are quite different from what Frederick Brooks observed.
Having developers check their code into a repository that’s tested all the time and deployed into production at least once per day is a great model to follow.
I hope you're planning to attend the DevOps Enterprise Summit, which runs from November 7—9. We have a spectacular line-up of more than 100 speakers, plus keynotes, DevOps workshops, breakout sessions, a community space for spontaneous gatherings, and an Expo Hall. See you there!
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
