
As is the case with many practices, DevOps has its fair share of destructive anti-patterns. And some of them, such as the often celebrated "hero" anti-pattern, described below, can seem like a good idea at the time, but create devastation in the long run.
Here's how to recognize anti-patterns, understand how they arise, and act to prevent them before they disrupt your DevOps projects.
Anti-patterns explained
In software development, a pattern is simply a description of how to solve a problem. Sometimes that pattern is evident after the software has been created, and sometimes specific problems suggest the implementation of a specific pattern.
Patterns create a vocabulary for talking about software solutions in a way that most people can understand.
An anti-pattern is a pattern that you use to fix a short-term problem at the expense of your long-term goals. The insidious thing about anti-patterns isn't that they don't work or fail outright, but that they work in the short term while causing long-term failure and pain.
You got out of the frying pan for now, only to get into the fire later.
Why anti-patterns are so sneaky
People follow anti-patterns because they are useful in the short term. "In some cases, even the anti-patterns are better than not doing it at all. It is important to recognize this and not kid yourself into a false sense of security," said my colleague Rich Mills, DevOps solution architect at Coveros.
The problem arises when an anti-pattern becomes the new normal and the team stops there. The ability to recognize that you are using an anti-pattern and knowing how to get out of it is a key skill for continuously improving teams.
If you must embrace an anti-pattern, also embrace what you'll need to do to move out of that anti-pattern as soon as you can.
The hero anti-pattern
Consider the classic hero anti-pattern, where one person or a small group goes to extraordinary lengths to deliver a project, usually by working a lot of extra hours to complete a project by the deadline.
To meet the timetable, however, the team may include substandard or dangerous code. In some parts of the industry, the hero pattern is not only in use but expected and celebrated. It has become a badge of honor to be a hero on a project. And, truth be told, there are times when teams need heroes.
But there are long-term consequences of the hero anti-pattern. These include burnout and the development of negative relationships between team members. The latter often stem from the resentment of the "heroes" who supposedly saved the project from the people who didn't go to the same lengths.
And when heroes burn out and leave the organization, they usually don't leave behind the history of what they did because, when they were struggling to finish, many things, such as testing and documentation, got left out. This leads to lower-quality software with less stakeholder confidence in both the software and the team's ability to deliver value.
In many cases, the hero anti-pattern is a reaction to management failure. The work wasn’t planned with the team’s capacity to deliver in mind. The team was asked to do more than it reasonably could given the schedule. There are many reasons why this happens, including regulatory demands, unmanaged stakeholder expectations, budget constraints, and unforeseen challenges.
How to fix it
One way to avoid dependence on heroes is to better manage the work scope, your deadlines, and expectations. This can be a tall order, but it is a way to finish your goals and not burn out your team.
Another way to not need heroes is to do risk analysis on the project to determine what could derail the work. This will allow the team to incorporate risk mitigation into the work schedule. It can also get the team to estimate the work beyond best case scenarios.
You can also estimate using a range so that you don't set the expectation that your estimates are certain and exact. Many agile teams use Fibonacci numbers for assessments for just this reason; they want to model the uncertainty in their estimates.
The continuous build anti-pattern
DevOps isn't immune to anti-patterns, and continuous build (CB) is one such example. It's what you get when you set up a continuous integration (CI) server without actually having a unit test suite or running code quality analysis on the codebase. You are building the software with each check-in.
(To clarify: CB is a subset of CI where you are only doing the first part of CI, and that is building. CI incorporates build, unit tests, and code quality static analysis.)
The CB anti-pattern is often used with legacy applications or with a team as they transition to agile and DevOps. It often starts out with good intentions—you decide to put a CI server in place and start building tests. You don't want to scare people with the large number of what you think are harmless issues by publishing code-quality metrics, so you tell yourself that you will put quality metrics in place after you've cleaned the code up.
But then feature requirements take the team's attention away, and it never gets back to a place where it has enough unit tests to start using quality metrics, and it never finds time to clean up the codebase. The team is caught in a place where all it is doing is building the software with each check-in.
One thing you often hear when you talk to a team about this situation is, "It is so much better now than it was." And this is often true; it is better to have a continuous build where you know if your software compiles and packages correctly than it was to build once a week, month, or longer and have to worry about making the software compile after an unknown number of changes.
Projects used to fail because huge parts of it were written in isolation and the differences couldn't be resolved in a reasonable timeframe. But just because things are better now doesn't mean they can't be even better.
How to fix it
The goal of CI is to have confidence that you can merge the code written by different team members, compile it, and have it still work as the code author intended. You can't do that without tests, and often unit tests are the right level of tests for that specific job.
The way to move continuous build into CI is to put that confidence back into the process by turning on unit testing and code quality analysis. Get your team, product owner, and stakeholders to agree to a change in your practices so that you will increase your unit test code coverage over time.
Get them to also agree to pay down your code quality technical debt over time. These are issues that were created over time, and it will take time to resolve them, but only if you can agree on resolving them.
Creating a DevOps silo anti-pattern
Many organizations start their DevOps journey by adding a new DevOps silo that becomes the middleman between dev and ops. This becomes an anti-pattern when an organization stops moving dev and ops closer together into one team and just keeps the DevOps silo.
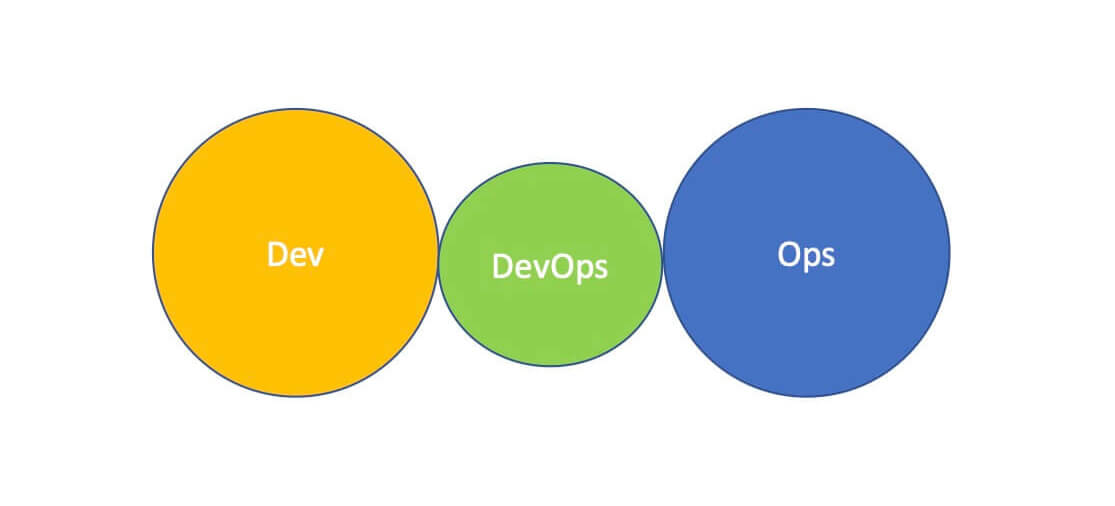
Creating a separate DevOps silo used long-term is an antipattern. Image based on work at devopstopologies.com - licensed under CC BY-SA.
How to fix this
When a DevOps silo is created, the goal should be to work the dev and ops teams out of a job by bringing them closer together so that they collaborate as a conscious part of the work. The DevOps silo should have a defined time to "live" as part of the transformation charter. It should be something reasonable, say one to three years, and after that time the silo should no longer be needed.
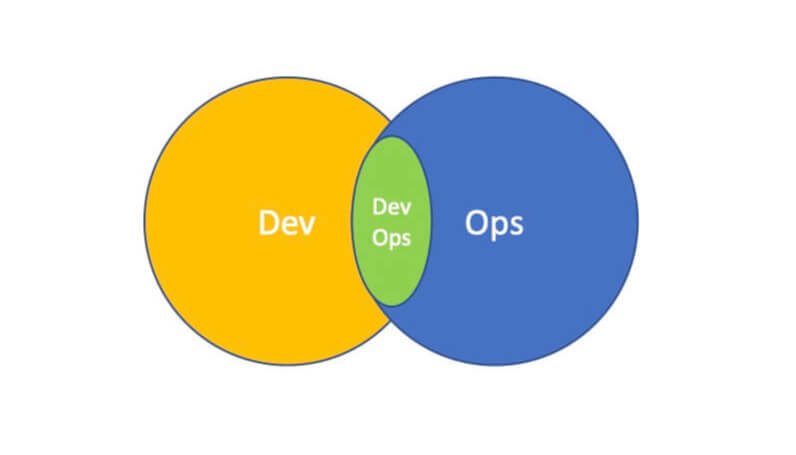
Within three years, your DevOps group should be structured like this. Image based on work at devopstopologies.com - licensed under CC BY-SA.
In fact, the whole organization should be incented to help make the changes required to no longer need that silo, and the organization should have overlapping dev and ops groups where the DevOps work is done in the intersection.
Selective automation
This is what happens when office politics interferes with DevOps. It occurs when specific functions are excluded from automation because the people in charge of that function don't, for whatever reason, want to have automation in their area. Being a bottleneck isn't their problem.
How to fix this
To get the most value out of automation you need to have specific criteria used to select what you automate. These criteria could be based around what is most repetitive, the riskiest part of your process, where automation will create the highest ROI, or what takes the most time.
Once you set that criteria you should stick with it and automate processes based on the priority generated from your selection criteria. Automating tasks that aren’t the highest priority can make your process less effective because it will create more backup in your critical path tasks as the automated, noncritical path tasks are completed faster.
Recognize the warning signs
I've discussed four particularly pernicious anti-patterns here, but there are more to be aware of. As DevOps continues into the mainstream of software development, you can learn how to recognize and avoid anti-patterns. They may seem reasonable at first, but they're bound to be damaging to your team—and your company—in the long run.
Want to know more? During my session, "Continuous Build and Other DevOps Anti-patterns," at the Agile + DevOps Virtual Conference, I'll explain more anti-patterns and how to combat them—including more about how to avoid the DevOps silos and selective automation issues raised above. The conference runs June 7-12, 2020.
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
