
Every building needs a foundation, and every piece of software needs an architecture that defines what it is and how it delivers for users.
Mark Richards, a software architect based in Boston, has pondered for more than 30 years about how software should work. His free book, Software Architecture Patterns, describes five architectures that are seen repeatedly in software systems.
Here are Richards' five foundational architectures, distilled into a quick reference of their strengths and weaknesses, as well as optimal use cases. For many cases, one single architecture is the best choice that will unite your code. For others, it may make sense to optimize each section of code with the best architecture for it.
Keep in mind that even though it's called computer science, it's often an art.
Layered (n-tier) architecture
This model offers a natural model for breaking up complex problems into smaller, more manageable parts that can be delegated to separate teams. Some feel it may be the most common architecture, although this claim is something of a self-fulfilling prophecy. Many of the biggest and best software frameworks—React, Java EE, Drupal, and Express—were built with this structure in mind, so many of the applications built with them naturally come out in a layered architecture.
The code is arranged so the data enters the top layer and works its way down until it reaches the bottom layer, which is usually a database. Along the way, each layer has a specific task, such as checking the data for consistency or reformatting the values to keep them consistent. It’s common for different programmers to work independently on different layers.
The Model-View-Controller (MVC) structure, depicted in the diagram below, is the standard software development approach offered by most of the popular web frameworks. It is clearly a layered architecture.
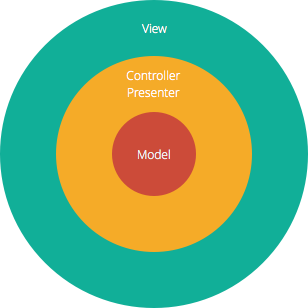
Figure 1: The Model-View-Controller structure. Source: Izhaki
Just above the database is the model layer, which often contains business logic and information about the types of data in the database. At the top is the view layer, which is often CSS, JavaScript, and HTML with dynamic embedded code. In the middle, you have the controller, which has various rules and methods for transforming the data moving between the view and the model.
The primary advantage of a layered architecture is the separation of concerns, which means that each layer can focus solely on its role. This makes it:
Maintainable
Testable
Easy to assign separate "roles"
Easy to update and enhance layers separately
Well suited to some data science and artificial intelligence applications because the various layers clean and prepare the data before the final analysis
Properly layered architectures will have isolated layers that aren't affected by certain changes in other layers, allowing for easier refactoring. This architecture can also contain additional open layers, such as a service layer, that can be used to access shared services only in the business layer but also be bypassed for speed.
Slicing up the tasks and defining separate layers is the biggest challenge for the architect. When the requirements fit the pattern well, the layers will be easy to separate and assign to different programmers.
Challenges of this approach
Source code can turn into a "big ball of mud" if it is unorganized and the modules don't have clear roles or relationships.
Code can end up slow, thanks to what some developers call the "sinkhole anti-pattern." Much of the code can be devoted to passing data through layers without using any logic.
Layer isolation, an important goal for this architecture, can also make it hard to understand the architecture without understanding every module.
Coders can skip past layers to create tight coupling and produce a logical mess full of complex interdependencies. Then it can start to look like the microkernel approach described below.
Monolithic deployment is often unavoidable, which means small changes can require a complete redeployment of the application.
This architecture is best for:
New applications that need to be built quickly
Enterprise or business applications that need to mirror traditional IT departments and processes
Teams with inexperienced developers who don't yet understand other architectures
Applications requiring strict maintainability and testability standards
Data pipelines built for data science in languages such as R and Python
Event-driven architecture
Waiting is a big part of life for many programs. This is especially true for computers that work directly with humans, but it's also common in areas such as networks. These machines spend most of their life just waiting for work to show up.
Event-driven architecture helps simplify creating software for this job by building a central unit that accepts all data and then delegates it to the separate modules that handle a particular type. This handoff is said to generate an "event," and it is delegated to the code assigned to that type.
One of the most common examples of this architecture is programming a web page with JavaScript. Most of the work is done by the browser displaying the web page, and the programmer has only to create small blocks of code that react to events such as mouse clicks or keystrokes.
The browser itself orchestrates all of the input and makes sure that only the right code sees the right events. Many different types of events are common in the browser, but the modules interact only with the events that concern them. This is very different from the layered architecture, where all data will typically pass through all layers.
Overall, event-driven architectures:
Are easily adaptable to complex, often chaotic environments
Scale easily
Are easily extendable when new event types appear
Are ideal for some of the new cloud models that deploy functions that run only when triggered
Challenges to this approach
Testing can be complex if the modules can affect one another. While individual modules can be tested independently, the interactions between them can be tested only in a fully functioning system.
Error handling can be difficult to structure, especially when several modules must handle the same events.
When modules fail, the central unit must have a backup plan.
Messaging overhead can slow down processing speed, especially when the central unit must buffer messages that arrive in bursts.
Developing a system-wide data structure for events can be complex when the events have very different needs.
Maintaining a transaction-based mechanism for consistency is difficult because the modules are so decoupled and independent.
Event-driven is best for:
Asynchronous systems with asynchronous data flow that occurs only occasionally
Applications where the individual data blocks interact with only a few of the many modules
User interfaces and other web-based JavaScript applications
Applications that may not run very often or run sporadically. The newer cloud functions-as-a-service models can save a dramatic amount of money because they only bill when the event triggers a function. The rest of the time they cost nothing to deploy.
Microkernel, or plugin, architecture
Some applications have a core set of operations or features that are used again and again in different combinations, depending upon the job. The integrated development environment known as Eclipse, for instance, will open files, annotate them, edit them, and start up background processes. The tool performs all of these jobs with Java code and then, when a button is pushed, compiles the code and runs it.
In this case, the basic routines for displaying a file and editing it are part of the microkernel. The Java compiler is just an extra part that's bolted on to support the basic features in the microkernel. Other programmers have extended Eclipse to develop code for other languages with other compilers. Many don't use the Java compiler, but they all use the same basic routines for editing and annotating files.
The extra features that are layered on top are often called plugins. Many call this extensible approach a plugin architecture instead.
Richards explains this with an example from the insurance business: "Claims processing is necessarily complex, but the actual steps are not. What makes it complex are all of the rules."
The solution is to push some basic tasks—such as asking for a name or checking on payment—into the microkernel. These can be tested independently and then the different business units can then write plugins for the different types of claims by knitting together the rules with calls to the basic functions in the kernel.
Many operating systems today, including Linux, use a kernel-style architecture, although the number of features in the kernel (the so-called size) is a matter of much debate. Some prefer the smaller microkernels and some like larger macrokernels that, while more complex, share a similar style.
Challenges to this approach
Deciding what belongs in the microkernel is often an art. It ought to hold the code that's used frequently.
The plugins must include a fair amount of handshaking code so the microkernel is aware that the plugin is installed and ready to work.
Modifying the microkernel can be very difficult or even impossible once a number of plugins depend upon it. The only solution is to modify the plugins too.
Choosing the right granularity for the kernel functions is difficult to do in advance but almost impossible to change later in the game.
Microkernel is best for:
Tools used by a wide variety of people
Applications with a clear division between basic routines and higher-order rules
Applications with a fixed set of core routines and a dynamic set of rules that must be updated frequently
Microservices architecture
Software starts out like a kitten: It is cute and fun when it's little, but once it gets big, it is difficult to steer and resistant to change. The microservices architecture is designed to help developers avoid letting their babies grow up to be unwieldy, monolithic, and inflexible.
Instead of building one big program, the idea is to split the workload into many smaller programs and then create another little program that sits on the top and integrates the data coming from all of the tiny ones.
"If you go onto your iPad and look at Netflix's UI, every single thing on that interface comes from a separate service," Richards said. The sidebars and menus filled with ratings for the films you've watched, the recommendations, the what's-up-next list, and the accounting details are tracked by separate services and served up independently.
It's as if Netflix—or any microservice—is a constellation of dozens of smaller websites that present themselves as one service.
This approach is similar to the event-driven and microkernel approaches, but it's used mainly when the different tasks are easily separated. In many cases, different tasks can require different amounts of processing and may vary in use.
The servers delivering Netflix’s content get pushed much harder on Friday and Saturday nights, so they must be ready to scale up. The servers that track DVD returns, on the other hand, do the bulk of their work during the week, just after the delivery of that day's mail.
By implementing these as separate services, the Netflix cloud can scale them up and down independently as demand changes.
Challenges to the microservices approach
The services must be largely independent, or else interaction can cause the cloud to become imbalanced.
Not all applications have tasks that can be easily split into independent units.
Some AI and data processing jobs take holistic approaches that can't be split into small parts.
Performance can suffer when tasks are spread out among different microservices. The communication costs can be significant.
Too many microservices can confuse users, as some parts of the web page may appear much later than others.
This approach is best for:
Websites with small components
Web applications built out of server-side JavaScript for Node applications such as React or Vue
Corporate data centers with well-defined boundaries
Rapidly developing new businesses and web applications
Development teams that are spread out, often across the globe
Space-based architecture
The heart of many applications is the database, and they function well as long as the database is running smoothly. But when usage climbs and the database falls behind because it's writing a log of the transactions, the entire website fails.
Space-based architecture avoids this by adding multiple servers that can act as backups. It splits up both the presentation and the information storage, assigning these jobs to multiple servers. The data is spread out across the nodes just like the responsibility for servicing calls.
Some architects use the more amorphous term "cloud architecture" for this design. The name "space-based" refers to the "tuple space" of the users, which is cut up to partition the work between the nodes.
"It’s all in-memory objects," Richards said. "The space-based architecture supports things that have unpredictable spikes by eliminating the database."
Storing the information in RAM makes many jobs much faster, and spreading out the storage with the processing can simplify many basic tasks.
Challenges with the space-based approach
Transactional support is more difficult with RAM databases.
Generating enough load to test the system can be challenging, but the individual nodes can be tested independently.
Developing the expertise to cache the data for speed without corrupting multiple copies is difficult.
The distributed architecture can make some types of analysis more complex. Computations that must be spread out across the entire dataset—such as finding an average or doing a statistical analysis—must be split up into subjobs, spread out across all of the nodes, and then aggregated when it's done.
This architecture is best for:
High-volume data like click streams and user logs
Well-understood workloads with sections that need different amounts of computation; one part of the tuple space could get powerful computers with large RAM allocations, while another could get by with much less
Low-value data that can be lost occasionally without big consequences—in other words, not bank transactions
Social networks
Mix and match
Richards spelled out his favorite five solutions, and there's a good chance they'll do exactly what you need. In some cases, the best solution could be a mixture of two—or maybe even three.
You can download his book for free. It contains a lot more detail.
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
