
Yad Vashem, the World Center for Holocaust Research, Documentation, Education and Commemoration, faces a big data problem of unparalleled gravity. The center holds over a petabyte of Holocaust-related documents and artifacts, including victim, witness, and survivor testimonies in many different digital formats. While this unstructured data is enormously valuable, it is also difficult to share.
“The contents of Yad Vashem's unique archives are of immense ethical, historical, and educational importance,” explained Haim Gertner, director of the Archives Division. “For the last 10 years, we’ve been dealing with the challenge of making this information accessible to future generations.”
To address this, the museum, together with Hewlett Packard Enterprise, recently created Israel’s first big data hackathon, "History Meets Innovation," with the goal of investigating new and compelling ways to present the material to future generations. The results demonstrated how big data analytics can bring cultural memories to life, while also showing that younger generations are passionate about their heritage.
The big data challenge
In addition to housing tens of millions of Holocaust-related documents, photos and artifacts, the Yad Vashem Archives currently include some 125,000 testimonies in video, audio, image, and text forms. In some cases, several different media formats are associated with the same person. For example, there might be a video or audio file of an interview with a witness, a transcript of the interview, and supporting documents such as birth and marriage certificates or camp records. And the testimonies continue to grow as staff members interview aging survivors in their homes. Currently, five to ten new interviews are conducted every day, and the pace of testimony gathering is increasing as survivors get older.
Interviews, using open-ended questions, typically last around three hours. Answers could be as simple as one word or as complex as ten minutes or more of uninterrupted speech. The testimonies are in a wide variety of languages, dialects, and accents.
Between 20 percent and 30 percent of interviews have been transcribed, Yad Vashem officials estimate. Some transcripts are in digital text format, but because Yad Vashem started gathering testimony in the 1950s, earlier transcripts were often hand-typed and later scanned as images.
The Archives also contain multiple testimonies from the same person, where statements were gathered over a period of time, rather than in one interview.
Prepping the data
Gertner, along with staff Avishay Danino and Yael Gherman, prepared a sample of some 16,000 testimonies for the hackathon. Most were in Hebrew, with English as the next most common language. The repository also contains testimonies in European languages such as Russian, Polish, German, and Yiddish.
Yad Vashem partnered with Hewlett Packard Enterprise on the project, and Sagi Schein, a research scientist at Hewlett Packard Labs, prepared the data to make it easier for hackathon participants to use. He converted the video to MP4, audio to Ogg format, and the images to PDFs. He also chained together multiple images that represented different pages of the same testimony into a single PDF file.
Contestants needed a simple way to access the data, so Schein built a simple LAMP (Linux, Apache, MySQL, Python) server where contestants could retrieve lists of testimonies and access individual items in each list by a unique identifier.
HPE made its big data analytics platform, Haven OnDemand, available to hackathon participants, and the contestants used the Haven OnDemand API to analyze the data and access the results of the analysis.The analysis included text extraction and optical character recognition (OCR) from Word and PDF files, and speech recognition (speech-to-text) from video and audio files.
Variations in speakers’ accents and noise in images and documents presented challenges. For example, scanned documents might have noise due to the reverse of the transcript showing through, handwritten notes added to the transcript, or creases, folds, and random marks on the paper. Issues like these made it difficult to reconcile instances of key words, such as the names of people and places.
Gertner noted that the spelling and pronunciation of people and place names are related challenges. For example, the name “Abraham” could have variations such as “Avraham,” “Avrohom,” “Avram,” “Avremaleh,” or simply “Avi,” and all could refer to the same person.
Running the hackathon
HPE Software’s Innovation Team, steered by project manager Karen Cohen, organized the hackathon, which was open to developers, students, academia, and HPE employees. More than 200 people submitted 43 ideas through the event’s website.
A team of HPE and Labs researchers then evaluated each team's ideas to determine which were most feasible to demonstrate within the allocated two-week window. They chose 16 teams, each of which was asked to develop a working prototype of its ideas, to be presented live at the judging ceremony in Yad Vashem's Edmond J. Safra Lecture Hall.
Mentors from HPE and Yad Vashem provided technical assistance with the Haven OnDemand APIs and the archive material. They also helped the contestants achieve the goal of having a working demo and creating nine-minute presentation for the judging ceremony.
Some entries focused on making the data accessible through an intuitive user experience, some used crowdsourcing to improve data quality by asking visitors to the site to identify text or audio that the technology did not understand, and some augmented the material in the database with additional research material available on the Internet, integrating with sites such as Facebook and Wikipedia.
The winning entry: Making testimonies searchable
First place was awarded to Testimonies Become Searchable, by Omer Barkol, Yaniv Sabo, and Inbal Tadeski, from Hewlett Packard Labs. This entry focused on direct, accurate, and coordinated search within audio and video testimonies.
 Figure 1: "Testimonies Become Searchable"
Figure 1: "Testimonies Become Searchable"
Barkol explained that, if someone were to search for a particular statement in a four-hour video, he would be unlikely to sit through the whole video to find where that subject appears. That's a problem because the older transcriptions are simple text files without any reference to timing.
To solve this problem, Barkol's team associated each phrase in the transcripts with precise locations in the video. “We used Haven OnDemand’s speech-to-text capability to convert the audio tracks to text, but because of language, dialect, and accent issues, some of the results weren’t very accurate,” said Barkol, “and the correlation between the text and its location in the video files had an accuracy of around 30 seconds for short videos, and up to four minutes for long videos.”
“As we investigated ways to improve the accuracy, we used an external speech-to-text package that supported Hebrew, but it was still very inaccurate. We realized that, on average, there was one correct word per every few dozen words. We were able to run a sequence-matching algorithm that used the correct words as anchor words, and this increased our accuracy to around plus or minus five seconds, regardless of the size of the video. For the demo, we began replay of any given phrase five seconds before its projected time to be on the safe side, and also to provide some context.“
The Testimonies Become Searchable interface allows the user to enter search text, and presents the results in the form of videos that can be played from the moment the search term is mentioned. Each instance of the search term in the video has a marker users can click to skip directly to that location.
During his presentation, Barkol demonstrated the accuracy of the algorithm by challenging the audience to shout out a random word to find in the archived videos. Someone suggested “Poland,” which Barkol typed into the application. It returned accurate results immediately, and Barkol clicked one of them to play a video at the point where the word appeared.
Runner-up: Summarizing testimonies
Second place went to "Testimonies to the ADHD Generation," which cut down long testimonies to short, bite-sized audio and video clips. The clips were incorporated into rich presentations, such as interactive pictures and maps, to bring the material to people with limited time and attention.
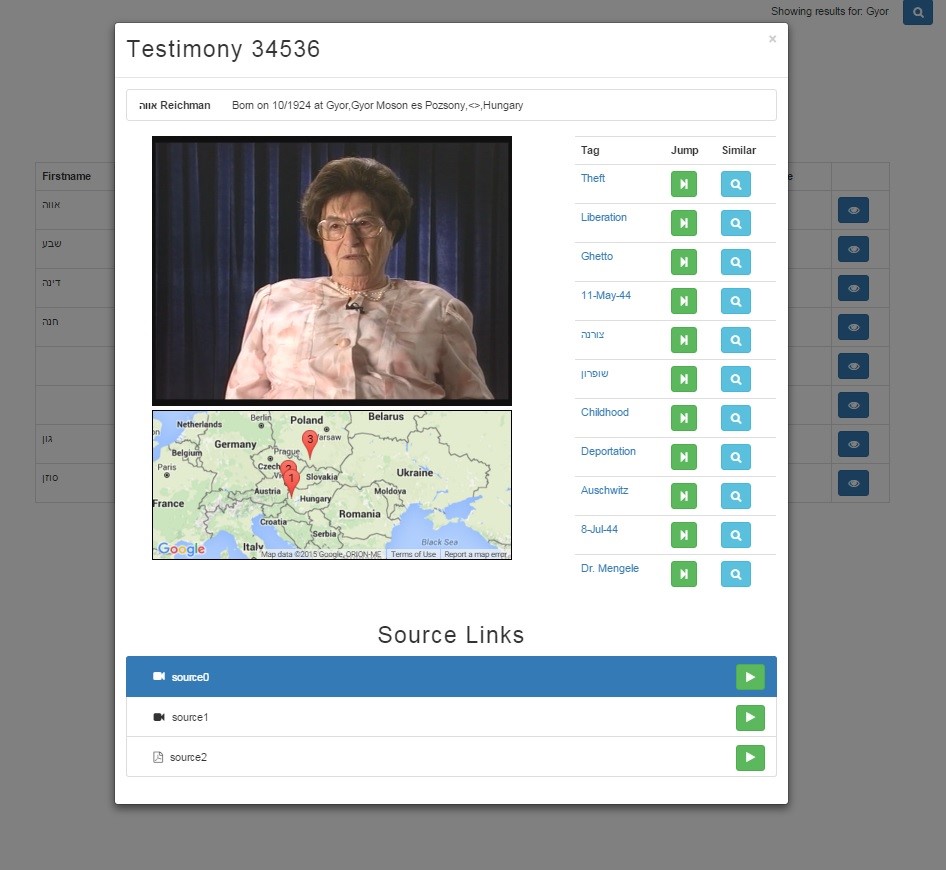
Figure 2: "Testimonies to the ADHD Generation"
The entry was submitted by Ilan Shufer, Yaron Burg, Olga Kogan, and Amit Levin, and was presented by Amitay Korn, all from HPE Software. “Our team decided to take a long shot and define an overall architecture with reasonable mock-up/proof-of-concept outcome," Korn said. "As such, our challenge was to carve out the core functionality and technology we defined as mandatory and implement it.”
Third place: Placing testimony in context
Uri Kalish, Tsila Cochavi, Yaniv Aharon, and Gali Brafman from HPE Software, and Amit Novick, a student at the Hebrew University of Jerusalem, took third place with "Testimonies in Context," a web application that shows Holocaust- and WWII-related items of interest, such as ghettos, camps, images, testimonies, and the advancement of forces overlaid on an interactive, dynamic map.
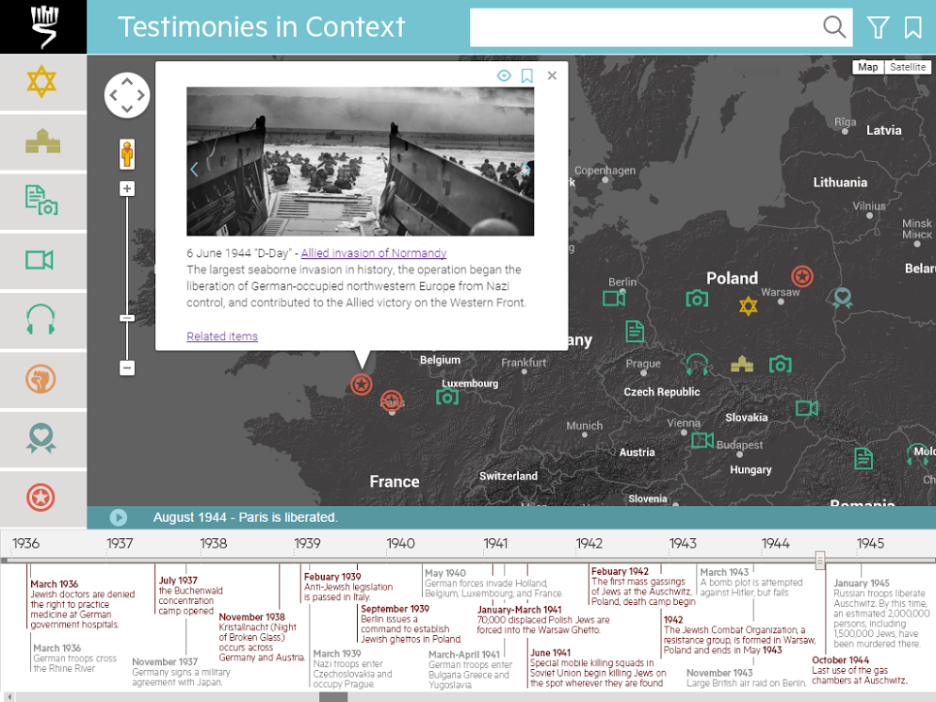
Figure 3: "Testimonies in Context"
Layering the data enables users to connect ostensibly disparate and disconnected events to create an easy-to-follow, personalized timeline. Kalish, who presented the entry at the ceremony, said, “The hackathon presented many opportunities for innovation. Our team chose to focus on presenting the testimonies within the context of their time and location, within an intuitive interface. We did this through layers on top of Google Maps, so that you can see events and testimonies from the same vicinity, and we developed our own dynamic timeline that syncs seamlessly with the map to show how events progressed”.
Bringing the past into the future
At the conclusion of the hackathon, Michael Lieber, CIO of Yad Vashem, said, “All cultural heritage organizations struggle with unstructured big data repositories, but Yad Vashem is a unique institution with a vast and still-growing archive of personal testimonies.”
Gertner added: “The ideas presented at the hackathon, and in particular the winning entry, demonstrated a true understanding of the problem domain, and demonstrated creativity and innovation in meeting the challenge.”
While Lieber was impressed with the technical solutions, he says he was particularly struck by the level of passion and commitment to the project that contestants demonstrated.
“The participants in the hackathon were 100 percent engaged from the start, and didn’t need any encouragement from us. We of the older generation sometimes look down at the younger generation as being superficial, with a short attention span. But when you make the right connections, you can see that this generation is no less intelligent, smart, and curious than the previous generation. The hackathon achieved the primary goal of investigating ways to make the data accessible. We also achieved a secondary goal of engaging a new circle of people who are now closer to Yad Vashem,” he said.
The hackathon submissions will now become part of Yad Vashem’s research into ideas that could be developed into full-scale digital experiences to encourage young people to engage with the testimonies of the ever-declining number of people who actually witnessed the Holocaust.
Keep learning
Choose the right ESM tool for your needs. Get up to speed with the our Buyer's Guide to Enterprise Service Management Tools
What will the next generation of enterprise service management tools look like? TechBeacon's Guide to Optimizing Enterprise Service Management offers the insights.
Discover more about IT Operations Monitoring with TechBeacon's Guide.
What's the best way to get your robotic process automation project off the ground? Find out how to choose the right tools—and the right project.
Ready to advance up the IT career ladder? TechBeacon's Careers Topic Center provides expert advice you need to prepare for your next move.
