
If you're going to automate testing in your delivery pipeline, you need to strike the right balance between environment fidelity—testing in a deployment environment that's similar to the user-facing environment—and the time it will take you to repair broken tests. I often see organizations with an acceptance test strategy that relies on an end-to-end clone of production—minus the data.
There's a better way: Break your tests into smaller components. In this layered automation strategy, you start out with fast tests on an isolated component and then gradually increase environment fidelity, replacing stubs by actual components, as changes progress in the pipeline. Your goal should be to reduce the overall cycle time from code check-in to the time when it reaches your customer's hands. I'll show you how to do it.
But first, here's why relying on production clones is a bad idea: The approach provides high environment fidelity, but it takes a long time to get feedback using this method because your tests will be slow to run and repair. The large test surface also makes it harder to diagnose the cause of issues.
You might be able to see errors the end user would face in the live system, but to get at the root of the issue you might have to jump through multiple hoops of log digging, ask for advice from colleagues, or even do some code-level debugging. So the time to diagnose issues goes up as the time to repair a broken pipeline increases.
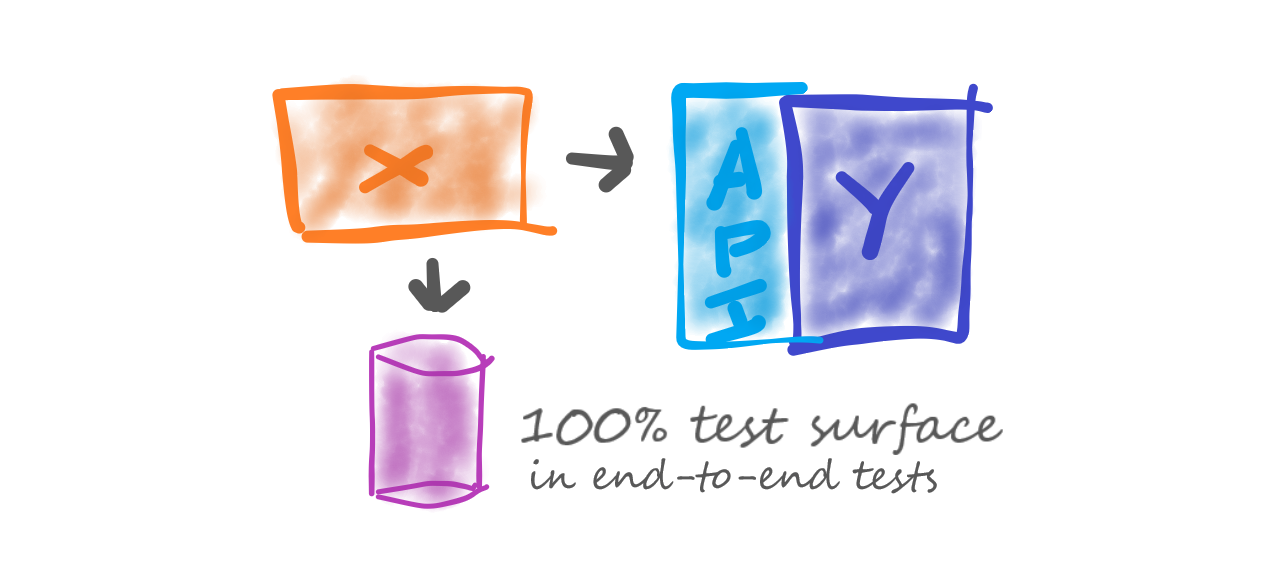
Figure 1: End-to-end tests with 100% test surface (entire system under test).
The alternative is to break down those tests. Here's how to do it.
Why organizations use production clones for all tests
Long-lasting broken pipelines and long feedback cycles go against the core tenets of continuous delivery and DevOps. Just as you strive to keep your build and unit tests green in continuous integration (CI), you should strive to keep your delivery pipeline green—and I don't mean by ignoring a failing test.
But because end-to-end tests can take so long to repair, teams tend to get on with other tasks, and failed tests start to pile up. Soon, having a broken pipeline becomes the default instead of a short-lived exception.
As a consultant, I've found this anti-pattern—a test strategy based mostly on end-to-end tests in a production replica environment—particularly prevalent in larger clients, typically due to one of the following reasons.
- In some cases the provisioning processes are not automated enough, so it becomes painful—or unthinkable, even—to have multiple test environments in the delivery pipeline. Thus, test engineers resort to keeping a few static end-to-end environments.
- In others, the client faces considerable challenges in terms of hardware, such as when working with Internet of Things devices or supporting a wide range of mobile devices. This leads engineers to believe that static end-to-end environments are the only realistic way to test use cases.
Even when no hardware is involved, if a product has a high number of variants—that is, it is officially supported across multiple combinations of operating systems, databases, SaaS vs. on-premises, etc.—then using static environments seems more appealing than dynamically provisioned environments. Containers have mitigated this to some extent, but large legacy systems are still cumbersome to containerize.
The above scenario is worse for software systems that have grown over the years, deepening the network of component dependencies to an extent that it becomes painfully difficult to stand up one component in isolation.
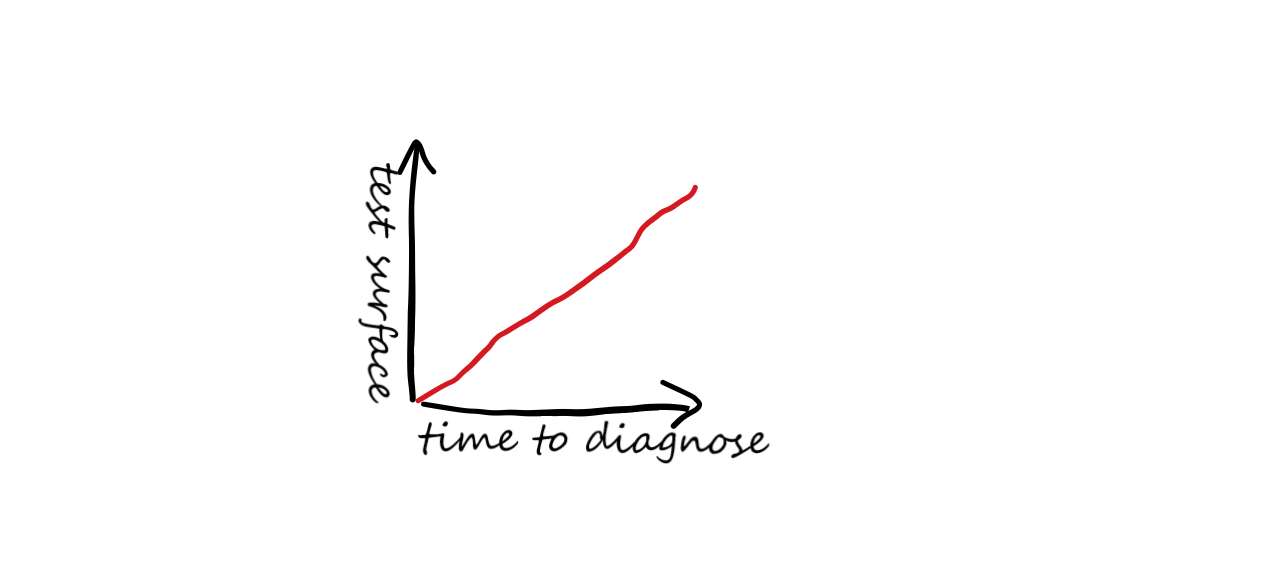
Figure 2: As the test surface increases, so does the time it takes to diagnose issues.
Your two keys to a better test strategy
There are two key factors to reduce time to feedback and time to repair tests:
- Establish clear test boundaries and the test surface.
- Progressively increase the test surface while decreasing the number of tests you execute.
As with system architecture, your aim should be to split system testing into smaller chunks so you can understand what actually happens during a test. That means that a first fundamental step should be to clearly and unequivocally identify which components of the system are being tested at each stage of the delivery pipeline.
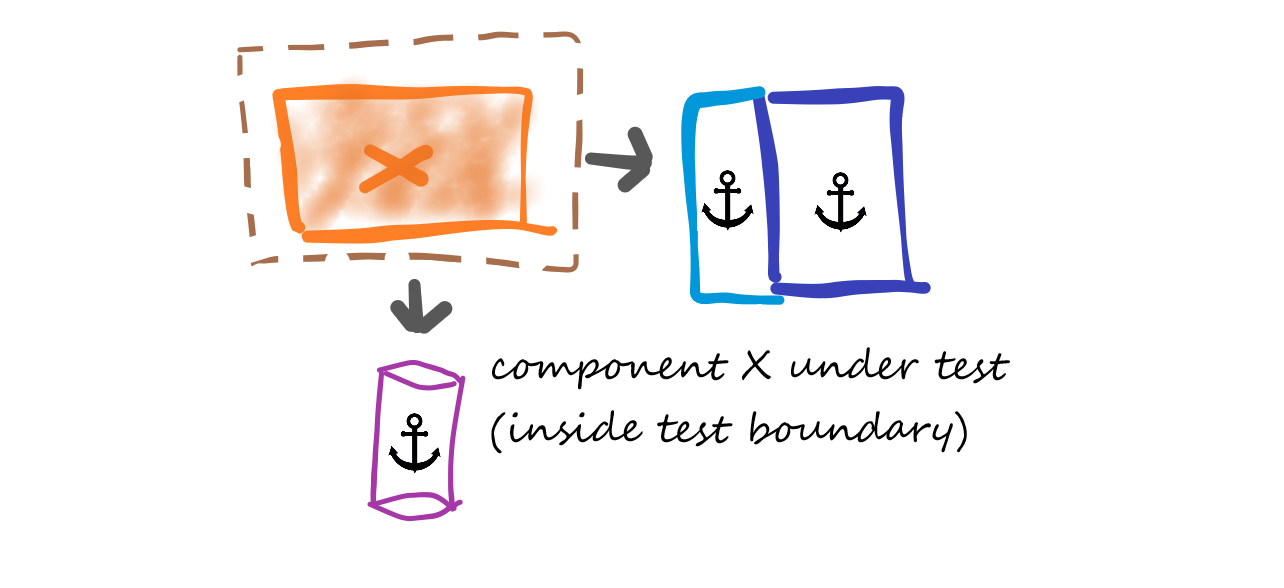
Figure 3: A test boundary highlights which components are under test—and which are not.
Those components are inside the test boundary for the current stage. All other components in the system are outside and can be simulated with mocks, stubs, or any other mechanism that guarantees repeatable outcomes.
The analogy to the experimental method is obvious. That method takes a systematic, scientific approach to research in which one or more variables are manipulated to determine their effect on a dependent variable.
The components under test (inside the test boundary) are like a dependent variable whose behavior is being observed. The components outside the test boundary are being controlled (with predefined inputs/outputs) to reduce the test surface. I like to call the latter the "anchors" for a test stage. Note that this strategy is possible even for some types of hardware components.
I once worked on a border-control system that relied on devices that included fingerprint scanners, signature pads, and cameras for face recognition. After abstracting the specific devices' software development kits with a common interface, we merely had to add a virtual implementation for each kind of device to control what output those devices provided to the system components. This effectively decoupled the tests of those components' internal logic from the input/output exchanges with the physical devices.
Decrease time to repair by narrowing your test surface
A progressive automation strategy that optimizes for quick feedback should start out with fast tests on an isolated component, simulating all of its dependencies. Then you gradually increase the test surface, replacing stubs with actual components, as changes progress through each stage in the pipeline.
Here's the key to a faster cycle time with this approach:
Every time the test surface increases, the number of tests you run should decrease by an order of magnitude.
When facing frequent failures in a given test stage, make sure the test surface in the previous stage is well covered with faster tests, rather than mechanically adding new tests to the larger surface.
Establish clear test boundaries
Let's say your build and unit tests in your delivery pipeline have passed with flying colors.
What's the smallest next step in the pipeline that can increase your confidence while supporting a fast feedback loop? You probably want to test the components that changed as a whole, but do so in isolation from other components. Your test boundary surrounds this component; every other component on which it depends is outside the boundary and should be controlled (i.e., simulated).
Note that you're testing only one component here. You're not testing its database connection, and you're not testing communication with other components or with third-party services. You are testing only the component logic and its outputs.
You might run dozens of tests at this stage—instead of hundreds of unit tests—and these should be reasonably fast, given that you're not actually calling the database or connecting to anything in the outside world. Answers from simulated components are fast and involve little to no processing.
Repairing broken tests at this stage might involve investigating logs and stack trace to look for unexpected errors or exceptions. Your unit tests passed, so this should be something involving any unintended side effects on other parts of the component that did not change.
Perhaps you'll need to add some unit tests around those other parts of the component to ensure that they can cope with the scenarios that failed.
Once you have that sorted out, enlarge the test boundary to include adjacent components. You might uncover differences between how you expect other components to respond (syntactically or semantically) versus how they actually do respond. But you don't expect to have to dig into the logic of your changed component to diagnose the issues found.
At this stage you will probably need to run a few dozen tests. You still want to run end-to-end tests in a production replica environment—also called a staging environment—later in the pipeline to ensure that esoteric issues don't unexpectedly creep in during production. But those should be a few end-to-end tests, not dozens—and certainly not hundreds.
The "set and forget" fallacy of production clones
You'll have a feeling of accomplishment when setting up static end-to-end environments. The initial high-fidelity characteristics should give you a sense of confidence in the tests as well as a feeling of relief that, once set up, the environment will require minimal maintenance.
But anyone who has been in charge of maintaining static environments will quickly debunk the notion that you'll have low maintenance costs for them. Think operating system patches, security updates, database migrations, incompatible third-party dependencies, and so on.
Another major overhead is that you'll typically need a static environment for testing different components and applications, with different test data setups. With today's accelerated software delivery, such environments can become a major bottleneck to getting your changes into production.
The ROI of a gradual testing strategy
To set up a pipeline that can support increasing test surfaces you must be able to create dynamic or ephemeral environments in an automated fashion. The cost of that capability is likely much higher than setting up a full end-to-end static environment.
But the cost of supporting gradual testing is an investment that will pay off on multiple fronts. Your investment in codifying and automating environment provisioning and configuration will pay off by reducing the time you'll need to replicate and test production environment changes.
Investing in developing and maintaining component stubs and mocks, or even just fakes, to control the test surface will reduce feedback time as tests run faster. Also, investing in reducing the test surface you need to investigate will reduce time to diagnose and repair a broken test.
Creating a high-fidelity, end-to-end replica of production in this approach means executing the same automated procedures as in any other environment, with mocked-out components. Such an environment no longer requires any special procedures to maintain; instead, it simply becomes the last in a series of ephemeral environments required to complete the pipeline.
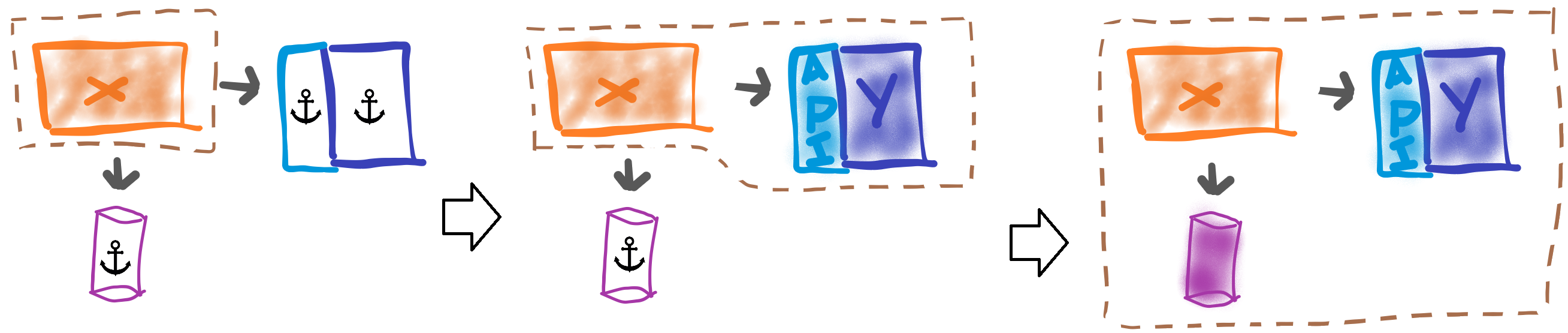
Figure 4: Full end-to-end tests with 100% test surface as just one more stage in the pipeline.
Another advantage is that, typically, component development teams will take care of developing and maintaining the component's mocks and stubs, in close collaboration with testers and IT operations.
Contrast that with having a centralized team for setting up static environments that ends up overloaded with work and is constantly juggling priorities. Ironically, those teams become bottlenecks to environment updates, rather than enablers.
Run this discussion of gradual testing by your team. Do the practices make sense for your organization? Have you tried it? Share your thoughts in the comments below.
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
