
Most IT professionals understand the importance of having the right monitoring and metrics in place to give them a pulse on infrastructure, code base, and facilities. With a focus on uptime and availability, extra attention is put toward efforts to identify a problem before end users do. Prediction and prevention of disruptions become central to your actions.
Providing high availability is important, but it is by no means the highest priority for IT or the organization. Business objectives and continuous improvement should be at the top of every team’s list of priorities, including IT. Unfortunately, with availability placed as the highest priority, monitoring and metrics are typically used by IT teams to constantly firefight issues. They are rarely used to experiment or innovate so that the teams can improve upon their own processes and tooling.
In an industry where failure is unavoidable, learning and innovating through feedback loops is your best course of action. Instead of focusing on increasing the time until your next failure, you should focus on decreasing the time it takes for your systems to recover after a failure. This is what monitoring should be used for.
Changes can cause system failures, but innovation requires change
Disruptions in service will often be the result of many contributing factors, conspiring together in unique and sometimes unrepeatable scenarios. The complex nature of our systems means failure is unavoidable and can only be fully understood in retrospect. While system failures can never be reduced to a single root cause, it is possible to confirm that the common cause of failure is, very broadly, change.
This creates an interesting conundrum for organizations. The company's desire to self-sustain through continuous innovation comes in direct conflict with IT’s goal of providing maximum uptime.
Innovation requires change, yet change can result in failure.
"Without deviation from the norm, progress is not possible" —Frank Zappa
The solution is to recognize that failure in complex systems is inevitable. What you learn and apply from that failure is what sets innovative companies apart and gives them an edge over the competition.
Constantly seeking a better way of doing something should not only be acceptable, but encouraged, despite the risk of failure. There is much to learn from failure, and once teams focus less on preventing it, they get better at repairing services and engineering in resilience. That combination leads to minimizing negative impacts for end users by repairing disruptions faster each time.
By reframing the goals of IT from "prevention of failure" to “learn from failure," a company will increase its operational maturity and the value of its products, rather than remaining static.

Source: VictorOps/Jason Hand
Learning through feedback loops
It's important to distinguish between knowing and learning. Learning means not only that you have acquired new knowledge, but that you have also applied that new knowledge successfully in a real-world situation or practiced using that knowledge with intention of improving a skill or action. This is one of the single most overlooked concepts about learning, especially in an organization.
Companies that focus on becoming learning organizations gain an edge over their competition. They leverage a variety of metrics to provide feedback in order to move their focus from maintaining to improving to innovating the tools, processes, and procedures.
The path to learning resides within feedback loops. Many organizations use US Air Force Colonel John Boyd's OODA loop for this task. By stepping through the process of observing, orienting, deciding, and finally acting, IT teams and organizations begin to truly understand and learn. Of course, throughout this cycle, new information and inputs will surface, at which point you begin by observing again. Iterating through this process is the path to real learning, which then enables teams to innovate.
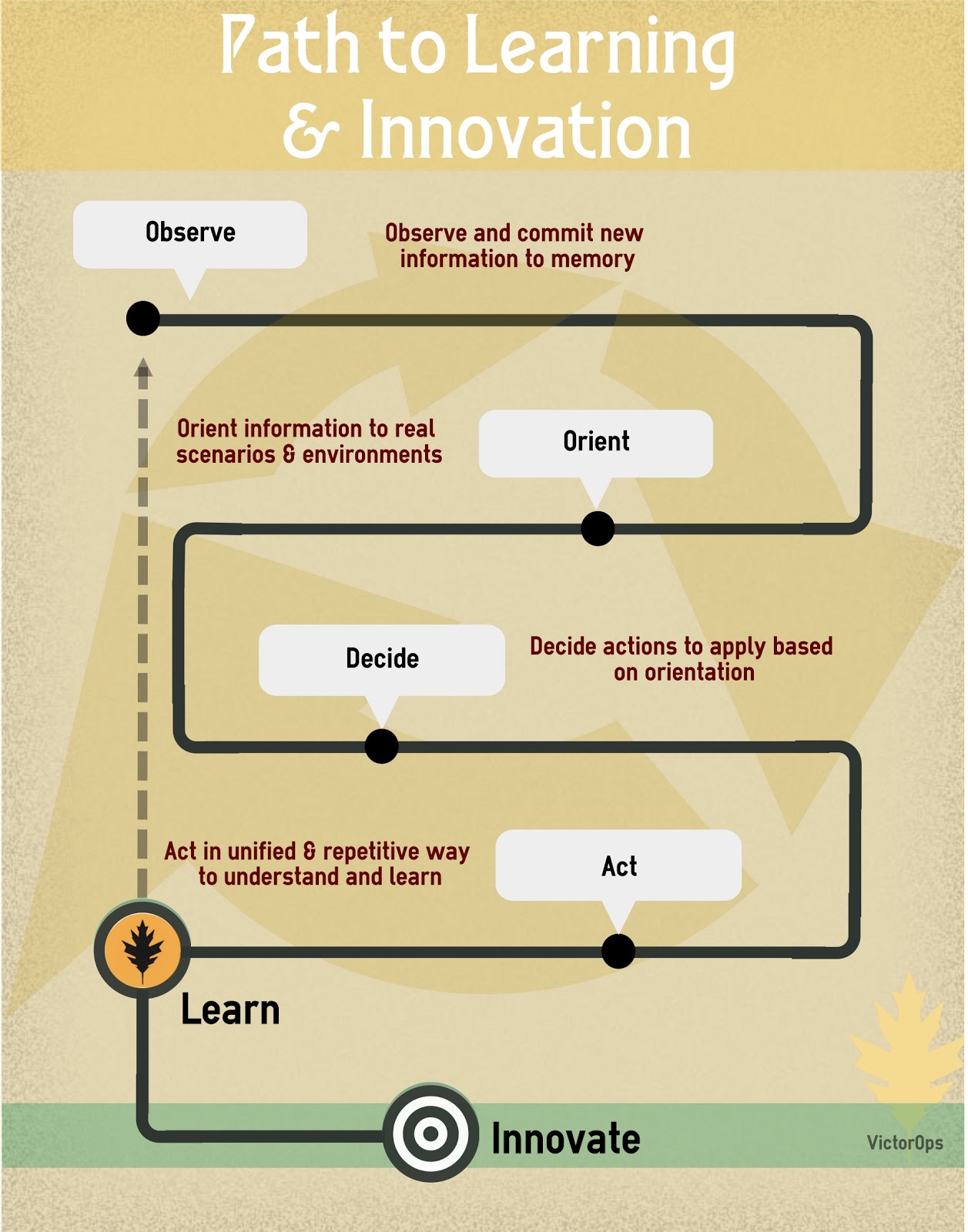
Source: VictorOps/Jason Hand
What does this have to do with monitoring?
The truth is, even if IT realizes the importance of learning and improving, it isn't always leveraging its tools in a way that facilitates it. Due in large part to our misaligned focus on failure prevention, IT professionals have historically found monitoring and logging to be useful only when things are going wrong and completely miss the opportunity to learn and improve by understanding the data right under their noses.
To be fair, this isn’t the case for all companies. It is much more common in larger and older organizations. Often, they are resistant to change and inadvertently stall out opportunities to learn and improve. Although teams may have aspirations to leverage monitoring and logging data to innovate their products and services, old-view constraints prevent that from being realized. Bureaucratic behaviors often impose change management and process control procedures that inevitably force IT to operate in a reactive manner rather than a proactive one.
The real value of metrics
Valuable context regarding what happened during a failure is usually available. Much of that data is generated and stored by the same tools that tipped IT off to a problem in the first place. But until you make a habit of understanding that context to identify incremental improvements, the full value of your monitoring tools and services will not be realized.
The result of underutilizing those metrics is that the IT department and the organization have no chance to learn, improve, or innovate. Continually understanding and responding to the feedback from monitoring and logging allows you to use information about events in the past to drive future actions.
MTTR, not MTBF
“High-performing IT teams achieve far better stability than lower-performing peers, with 60 percent fewer failed deployments and a mean time to recover (MTTR) that’s 168 times faster. It’s their use of DevOps practices that sets these top performers apart from the pack.” —State of DevOps Report (2015)
Rather than placing focus on protecting systems and engineering out the possibility of failure, focus on continuously repairing systems and engineer for the possibility of failure. Increasing the time between failures shouldn't be the primary objective. Instead, a focus on reducing the time it takes to repair a failure should be the aim. (This is what Netflix and many other major web properties do.)
Once IT teams have shifted their focus away from mean time between failure (MTBF) and more toward reducing the time it takes to repair from failure, services naturally become more resilient and reliable. The distinction here is that because IT is now focused on learning. it discovers and applies improvements to the system as a whole, making complex systems capable of absorbing multilevel failures rather than trying to prevent them. This results in a reduced MTTR, which means there is a smaller chance that a disruption will have any real impact on end users.
Reliability and resiliency over availability
Once your focus is on repairing systems faster, you can create space to explore, experiment, and develop new ways to provide bleeding-edge products and services. The byproduct of a highly reliable and resilient system is a highly available system. By shifting your gaze away from simply maintaining systems and focusing more on improving them, you increase value across many fronts. The IT department provides more value to the business, and the business provides more value to the end user.
Want to learn more about how monitoring & alerting can make your organization smarter? Join the webinar I'm hosting on June 9th for a deeper dive into this topic.
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
