
"The idea behind the deployment pipeline is to model the part of your project's value stream that goes from check-in to release, and then to automate it."
This quote, from Jez Humble and Dave Farley, preceded the publication of their book Continuous Delivery.
Their starting point was to model the value stream from commit to customer. Getting to full automation was the ideal. However, in many enterprises there are multiple manual steps involved in the value stream: approvals, checks, audits, and so on. The argument for full automation is still valid but frankly is more of a utopia for these organizations. And that's just fine.
I'm often asked by engineers who have automated their build-test-deploy pipelines how to involve the rest of IT in the delivery. They're still at a loss on how to bring the other teams involved in the delivery process on board. For example, it's not uncommon in enterprises that a release to production requires approvals from change control boards, security teams, legal/compliance teams, networking teams, and traditional ops teams.

Image 1: The build, test, and deploy pipeline. (Click here for larger image in new tab.)
The pipeline in image 1 represents only a small fraction of the commit-to-customer value stream. Yet we focus most of our efforts on this partial view of the delivery process.
What happens when you map your value stream
Let's look at a real example from a client in the financial sector that wanted us to help speed up its delivery process. As with other clients, the pipeline view they presented only slightly more complex than the one from image 1:

Image 2: The client's initial pipeline; build-test-deploy with more tests and checks. (Click here for larger image in new tab.)
But those were just the automated bits of the pipeline. And after running a value stream mapping session, we found out about all the other activities that were necessary for a release to happen:

Image 3: The client's full pipeline (real value stream)-a single sequence of steps although split into two lines here. (Click here for larger image in new tab.)
It turned out that the infrastructure and database teams had strong involvement in any nontrivial release, but because their work was mostly manual, it was not visible in the delivery pipeline. This was a very different picture from the pipeline view in image 2.
[ Special Coverage: All in on All Day DevOps ]
Beyond build-test-deploy (local) optimization
So what's the problem with a build-test-deploy pipeline? Does it not encompass most of the typical tasks that devs and ops should care about? Yes, and that's fine. Automating all these is valuable, but we should understand it's a local optimization when seen in the context of the full delivery chain. While there's value in automating the build-test-deploy bit, we should prioritize removing the biggest delivery bottlenecks first.
Going back to our client example, provisioning new infrastructure could take anywhere from several days to weeks, with a ticketing battle between dev and infrastructure teams taking place more often than not.
Also, deploying any change involving databases would require DBAs to run backups and pre-deployment and post-deployment checks—everything done manually. We're talking about long hours if everything goes according to plan, and even longer and painful rollbacks if it doesn't.
These real-world examples, while extreme, highlight that there can be orders-of-magnitude-bigger bottlenecks than shaving off minutes from a build or even an hour from the acceptance test run. Again, while there is value in the build-test-deploy optimizations, other parts of the value stream might be hindering delivery speed much more.
Evolving the value stream to deliver faster and more safely
In large organizations, the longest wait times are often at the boundaries between teams where artifact and resource hand-offs take place. Fixing them can be hard, possibly requiring changes in workflow and team organization. But the benefits can be 10 or 100 times higher than automating only the build-test-deploy functions.
The good news is that our value stream can evolve over time. (And with the rise of pipeline as code, it's very easy to play around and model future states of our pipeline.) It's all too common to fall into this binary-condition trap: If we don't have a fully automated pipeline, we're not doing it right.
We can and should have a roadmap for our journey to faster delivery with full automation (again, we might never get there, and that's fine). Fast feedback is a laudable goal, but how do we know when it's fast enough? If we focus instead on getting faster and faster feedback, then it becomes more concrete and measurable.
Back to our client example. Imagine we propose to go all out on infrastructure as code and have development teams provision their own resources with embedded corporate policies. Technically, we'd need to adopt some tooling such as Terraform, Ansible, CloudFormation, etc. (see image 4). But we'd need some organizational changes too, with the infrastructure team being dismantled or vastly reduced. These are massive changes that would take a long time and can drain staff motivation in the process.

Image 4: A target pipeline with automated provisioning using infrastructure-as-code. (Click here for larger image in new tab.)
Let's rewind a little and try to think about the smallest change that can help us reduce the provisioning bottleneck. What's the real problem? The infrastructure team doesn't trust that the provisioning requests are sensible and adequate. Development teams don't trust that resources get provisioned as requested. Fundamentally, there is a lack of trust (a cycle of mistrust) at play here.
Deployment verification tests (DVTs) are a simple technique to kick-start collaboration between these two teams. While such tests have been mostly used for validating application deployments, we have found them very useful for verifying that the underlying infrastructure meets the application requirements, before actually deploying into it. I like to call them "infrastructure verification tests" (IVTs). Available in multiple languages (Pester on PowerShell, Serverspec on Ruby), they're low-effort/high-value in this situation.
Developers can now provide clear, executable tests (the IVTs) along with their infrastructure requests. This will help the infrastructure team validate how the resources should look and determine if they were created correctly.

Image 5: A pipeline with manual provisioning but running infrastructure verification tests (IVTs). (Click here for larger image in new tab.)
This first, low-effort step does not disrupt the current workflow of the teams, yet it introduces the seeds for increased collaboration. With time, that collaboration will generate the much-needed trust for introducing more disruptive changes such as infrastructure as code and automated provisioning of resources.
The pipeline gets longer with the introduction of the infrastructure verification stages for test and production infrastructure. But the overall delivery time is reduced because there is agreement on the infrastructure request and any response gets validated much faster.
Note: Configuration files for the example pipelines (pipeline as code) used in this article can be found on GitHub.
Collaboration beyond IT
Making your IT workflow map from commit to customer is key. But in most enterprises there are also nontechnical participants in this value stream: legal, marketing, compliance, etc. There is no reason not to include them in the pipeline. We might uncover bigger bottlenecks in handovers from IT to these teams and vice versa. (Is anyone still dealing with lengthy requirements documents that take weeks to approve by business analysts?)
And why restrict ourselves to the commit-to-customer value stream? The full value stream is idea-to-customer. We can take DevOps collaboration beyond IT (some call it BizDevOps) by mapping the full value stream, identifying the biggest bottlenecks today, and improving collaboration between teams inside and outside IT.
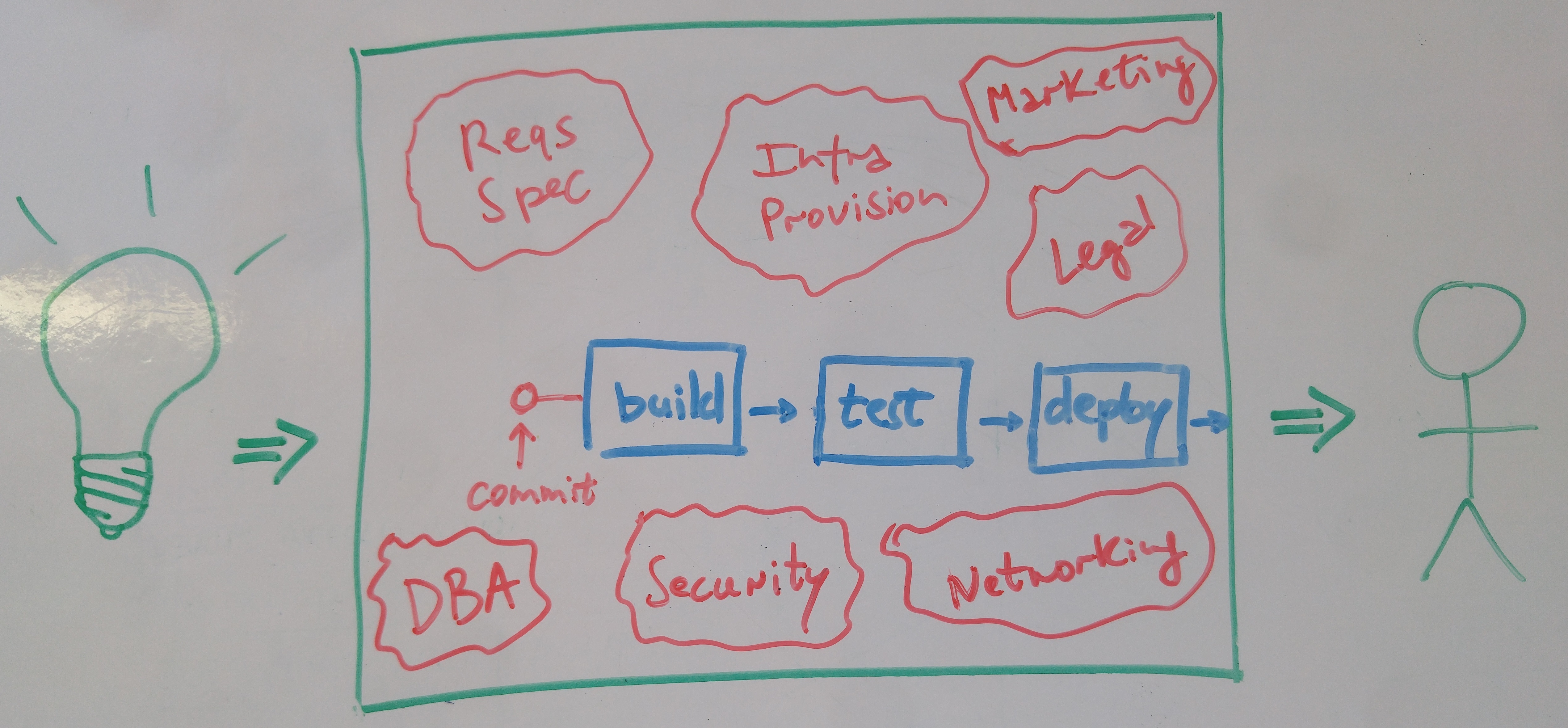
Image 6: The idea-to-customer value stream in the enterprise typically includes a lot more than build-test-deploy.
For more on how to use delivery pipelines to highlight bottlenecks and break down team silos, come to my presentation, "Everyone is Part of Continuous Delivery," at All Day DevOps. Another important aspect of inclusive pipelines that I will cover in the presentation is how to provide relevant information to nontechnical participants, such as what's left to do and how long it will take before this change is in my customers' hands.
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
