Is bad test data killing DevOps?
Test data used throughout the application lifecycle is stale, dirty, or polluted. The lack of adequate test data is eating into productivity gains from agile and DevOps investments because testing failures are slowing down the speed of software delivery.
Organizations that have adopted DevOps have shown progress in many areas, but according to my testing peers in various industry groups and organizations, quality is not improving at the pace or scale required.
Perhaps you are automating testing, doing all of the required unit tests, focusing on code coverage, and adding in some Selenium for good measure. How can quality be going down? You cannot automate your way out of quality issues, and it's difficult to reproduce defects when everyone on your team doesn't have access to the same data—or, worse, when the same test is executed with dirty, used data.
What you need is test data and a strategy for leveraging it. Unfortunately, most people aren't thinking about this at all. They're so focused on speed and everything-as-code that they're not thinking about quality—and that leads to quality failures.
Here's the problem with bad test data—and how you can fix it.
The infinity loop is wrong
You're probably familiar with the infinity loop for DevOps, but you might have overlooked the first cause for quality failures in the diagram. Here testing is isolated to a single step in the continuum. Simply shifting left to test earlier, or shifting right and testing in production, is not the answer.
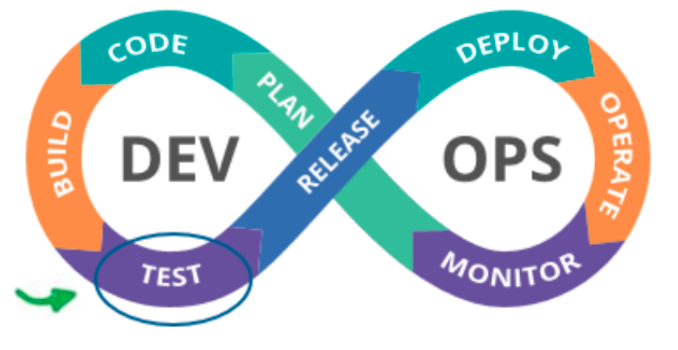{kind=link}
The infinity loop for DevOps. Source: United States Air Force.
You need to rethink the wording of the infinity loop to elevate quality and testing. It needs to be woven into the essential fabric of the loop. You need to be more specific during each and every phase, step, and transition to amplify testing and quality.
Holistic testing is more than automated testing
"The term continuous testing has been used and abused," said Janet Gregory, co-author of Agile Testing: A Practical Guide for Testers and Agile Teams and the founder of the Agile Testing Fellowship. The term was intended to mean focusing on testing and quality across the entire effort, but it has been hijacked. So I use the term holistic testing here to encompass an all-quality focus.
The components of that focus include:
Discover, plan, and understand—Identify risks, test assumptions, and build prototypes.
Build and deploy—Instrument code and automate tests, including stories, features, infrastructure, pipeline, quality attributes—the whole system.
Release, observe, and learn—Test in production and observe how customers use the product and what should be adapted.
Phantom defects abound
The obvious and more talked-about reasons for failures in testing cycles include a lack of test planning, gaps in skills and training, and overly fragmented test cases. We know software is still tightly coupled, and when organizations adopt agile practices, there can be a misplaced belief that all architectural design just "emerges."
Nothing could be further from the truth; even with agile practices, you still need to deliberately focus on software architecture. Think of building a hut versus building a skyscraper. You may be able to cobble together a hut without too much advanced thinking, and the architecture of the hut would "emerge." But that doesn't work for skyscrapers.
Failed tests cost the enterprise software market $61 billion per year, with nearly 620 million developer hours wasted on debugging software failures, according to a 2020 report by Undo Corporation and Cambridge Judge Business School. This amount is staggering, but it happens because we can't reproduce the defects, so they become "phantom defects."
The challenge: Expanding the narrative beyond asking how
The mad dash to automate testing has delivery teams asking, "How will we test this?" But if you are staying true to holistic testing, you need to ask a broader set of questions:
What should this test accomplish (why test this specific feature or capability)?
How will you test this?
What data do you need?
The determination of what to test and how to test it is the decision of the architects, the engineers, and the business. The key to effective and fruitful testing is having an intentional focus on defining, acquiring, and managing the data used for testing.
Data for DevOps
The types of data needed for testing are broad, representing the type of testing: unit, security, performance, integration, end-to-end, usability, and so on. Beyond the types of data, many other considerations are often overlooked when gathering test data, such as:
What is the domain, and are there unique requirements for specific industries such as aviation, banking insurance, and healthcare?
Are there regulatory constraints regarding the test data you might want to use, including personally identifiable information?
Are there governmental classification levels to apply, such as the Department of Defense's Impact Level 2?
Is the entire team aware of the architecture, user requirements, and quality attributes?
Who makes the test data?
Often, test data is created as an afterthought, and the responsibility is loosely defined or left completely undefined. Generally, test data will be made by some combination of developers, QA testers, security testers, and database administrators. Each of these folks approaches it from a different vantage point.
Developers focus on white-box testing, where it is based on knowing what the code looks like. Their data usually represents the best case, with their focus being on writing new features quickly.
QA testers often drive their data efforts using spreadsheets and may even inherit the developer data. When they can, they will swarm to use masked production data.
Security testers create their data almost exclusively manually, using an ad hoc approach. The focus on DevSecOps is helping a pivot toward intentional generation of security test data.
DBAs feed the entire team by bringing production data into lower environments. They may apply masking techniques.
Pitfalls with production data
The access to and proliferation of production data into test environments needs to create a showstopper moment. It is true that production data represents an accurate image of the data that works well; however, it covers only 70% to 75% of the scenarios. Production data also misses the edge cases that cause the headline defects.
But the most important reason to reconsider use of production data is that it is usually not masked or de-identified.
According to the State of Database DevOps 2019 report by Redgate (PDF), 65% of companies are using production data for testing and only 35% of them are using masking techniques. The result is a vast cyber-risk footprint. It is very difficult to mask and de-identify data, so the result is that delivery teams are told to be careful in handling the data.
So where should test data come from? You should take a blended approach: You need to build, borrow, and buy.
Using manual techniques, interacting with the front end, and applying business rules to synthetic data generation tools form a strong basis for a test data suite. Borrowing data includes taking selective production data and masking it. Borrowing data also includes referencing prior systems and applying the extract, load, and transform process. Buying data from other corporations or data brokers, using publicly available data, or even web scraping can round out your approach to creating a robust suite of test data.
Here are a few principles to apply to your test data acquisition approach:
Explore the data
De-identify
Validate
Build for reusability
Automate test data generation
With intentional focus on test data, there are still two major stumbling blocks to avoid: preserving test data and loading /reloading it. If you don't have a valid, repeatable initial state, a test is not valid.
Technology is not the issue
What does all of this have to do with DevOps? As with many challenges in applying DevOps principles, applying technology is not the issue, nor is it the solution to addressing test data in an organization.
Delivering value means delivering quality. Delivering quality demands holistic testing that can only happen with robust test data management, test data management tools, and integration into the value stream and DevSecOps pipeline.
Join me on October 5, 2021, at DevOps Enterprise Summit Virtual - US, where I will be discussing these ideas further so your organization can deliver ultimate value to end users at the speed of relevance.
©2021 MITRE Corporation. All rights reserved. Approved for public release. Distribution unlimited PR_20-02784-6